

���ϿƌW�����˹����ܣ�����|�f���ϔ�����
�C���W�����g�����܉F���ϿƌW��׃�

�@��������O�͵�ҕ�l�ď����ߣ�һ����Ļ�L�Ӳ�����һ���Д����c��̖�������֙C�����ǣ�ÿ�����^���v�㸩��Ճ��ߺ����k���ң�Nicola Marzari�����Ȳ�������������չʾ��“�@���ҵ��֙C��”���f��“��2010���_ʼ�������rӋ���������ӽY����”��
��������ʿ��ɣ����ʿ�������WԺ��EPFL��������W��Marzari��ጵ��������֙C���H���M40������������������X���M��С�r������ɵ��΄��������WӋ�㡣�@һ���e���H�@ʾ���^ȥʮ���gӋ�㷽ʽ���M����Ҳ���҂�չʾ���\�㷽����׃���ϿƌW�о���·�Ŀ����ԡ�
��Marzari���_�����_�l�²��ϵķ���——���\���`���`ײ�l�F�²��ϣ������ڌ������ɷ�M���ĵy������——���c־ͬ���ϵ�ͬ��һ������Ӌ��C��ģ�͙C���W�����g���ɔ����fӋ�Ă��x���ώ졣��ʹ�nj��ʧ��������Ҳ���ṩ���õ���Ϣ��
���M�܂��x���������S����ȫ���ڼ��O�������̎����_ʼ�M�пs�p��ͨ�^�Ҍ��A�ڌ��ԣ�ᘌ��ض��đ��Á��Y�x�кϳɺ͙z�y�ărֵ�IJ��ϡ����磬�����ܷ����錧�w��^���w���ܷ��������F�Լ��܉���ܶ��ĉ����͜ضȡ�
�����ݴ�W��������У�IJ��ϿƌW�ң����ϿƌW�I������Ceder��ʾ������ϣ�������������Ԍ��F���ϿƌW�о����ٶ��cЧ�ʵľ��w�S��“���ڬF����ϵČ��ԣ��҂����ֻ�˽����е�1%��”�ɴ�ָ���������F䇵����ӣ��@�N�������״κϳ���20���o30�������ֱ��1996��ű����J���������δ����x��늳��IJ��ϡ�“�����@֮ǰ���]�˜y���^����늉���”Ceder�f����
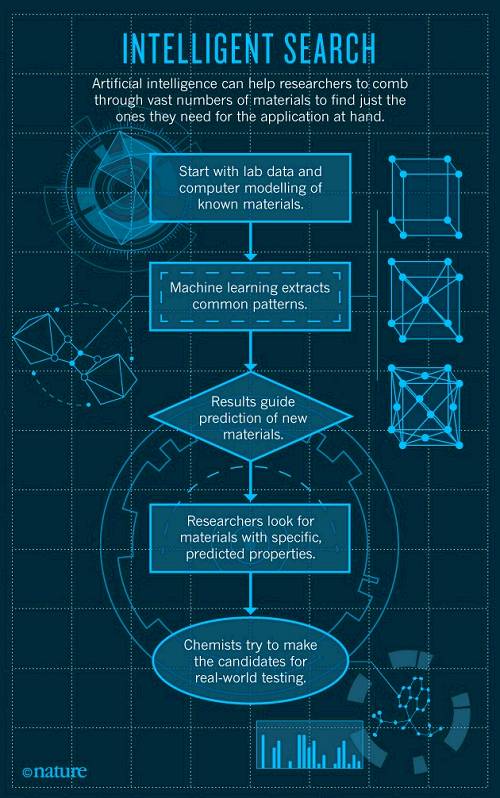
��������������������������Ҫ�IJ��ϔ����죬���������f���ʮ�f�Ļ����MarzariӋ�����ڽ�����Щ�r���Ƴ���ɣ�IJ�����Ӌ�����@�ܵ�Խ��Խ�V�����Pע��
�����ڂ��صۇ��WԺ���θ�Ժ�L�IJ��όW��Neil Alford�����`�����κ�һ�������죬��ָ����“�F�ڣ�����������c��Փ���ܼ��������ں���һ��”
�����M���ѽ�������O�룬���Ǐ�Ӌ��C�A�y�^�ɵ��F������ļ��g���s߀�к��Lһ��·Ҫ�ߡ��F�Д�����߀�]���ռ{������֪���ϣ����e�f���п����Բ��ϡ�
�����Ԕ����ӵ��о���ijЩ������Ч��������һЩ���υs�o�á����⣬��ʹ�҂�����X�ϺY�x��ijһ��Ȥ���ϣ����m�ϳɹ���ҲҪ�ĕr���ꡣ“�҂��������L�O�룬�s�o�����T���`��”Ceder�f��
�����M����ˣ��о��ˆT������������������Č��صȴ�����ȥ�ھ������܉��_���������Դ���C���ˡ��t�������ͽ�ͨ�\ݔ�I��Ą��r����֥�Ӹ�������Z˹�ݴ�W��Ӌ����ϿƌW��Giulia Galli��ʾ��“�҂����ڹ�ͬƴ���@�K���ƴ�D����ÿ����λ�����_�wλ�����ϵ��A�y�͕��ɞ�F����”
��������M���l
����21���o�����ڄ�����ʡ�����WԺ��Ceder�ܵ����r�������MӋ���Ć��l���뵽���Ԕ����ӵĸ�ͨ�����ϿƌW�о�������“���䱾�����ԣ������M�����µ��ί����������E��”���f��“���������t�W�ṩ�˔����@�˵Ļ��A�Զ�����Ϣ��”
���������룬���S���όW�ҿ��Խ��b�z���W�ҵ����������S�����όW�ҿ�����DNA�A������������Ϣ���a��ʽ�������N�������M�о��a���M���_��“���ϻ���M”��
���������룬��������O�댍�F����ô���a����ڽM�����o���ϵ�ԭ���c����У��Լ������ľ��w�Y���С�2003�꣬Ceder�����ĈF��״�չʾ�������WӋ�㔵��������A�y���ٺϽ�Ŀ����Ծ��w�Y�����@���²����аl�I���~�����P�Iһ����
�����^ȥ�����㌦�ڳ���Ӌ��C���f���@�ӵ�Ӌ������y�ֺ��M�r�g���C��Ҫ���v�����Lԇ���v������ʧ�������ҵ�“���B”��һ�N����������������������Ų��Լ����w�Y����
����2003�꣬Ceder�F���Փ����ָ����һ�l�ݏ����о��ˆTӋ����һ��С�Ͷ�Ԫ�Ͻ�����ij�Ҋ���w�Y����������Ȼ���OӋ��һ�יC���W���㷨���Ď�����ȡģ�ͣ��A�y���ͺϽ������ܻ��B���㷨ʮ����Ч�����s�p��Ӌ��r�L��
����Stefano Curtarolo�f��“��ƪՓ�Ľ�B�˽��O���ό��Թ��Î죬���Ô������aȱʧ���ֵ��O�롣”ͬ�꣬���x�_�о�С�M���ڱ����_���{���_��ķ�жſ˴�W���k���Լ��Č���ҡ��S����һ�O������˃ɂ������Ŀ��
����2006�꣬Ceder����ʡ���������˲��ϻ���MӋ���������㷨�ĸ��M�汾���A��늄���܇늳ص�䇻����ϡ���2010�꣬ԓ�Ŀ�Ѱ����˽����f�N���x�����“�҂��ĬF�в������֣��������ľ��w�Y��——�Ą��@��������Ԫ�ز�Ӌ��Y����”Ceder�F꠵�ǰ�ɆT Kristin Persson�f����2008�꣬���ᵽ�������������ڂ�˹���������Ҍ���Һ����^�m���M�Ŀ��
�����c��ͬ�r��Curtarolo�ڶſ˴�W�O���˲��ϻ���M���ģ���ע�о����ٺϽ�ͬ���Ԫq�������_�֗�ٺ���W���q���ݺ���ɫ�Ѓ��w��ĺ��о����ĵ��о��ˆTһ��Curtarolo��K��2003����㷨�͎�lչ��AFLOW��һ���܉�Ӌ����֪���w�Y�����Ԅ��A�y���ͽY����ϵ�y��
������ʼ�о��F�����о���Ҳ����ͨ��Ӌ����dȤ������һ���ǻ��W���̎�Jens Nørskov���ڵ������g�WԺ���g�������@�NӋ����о���������ˮ�ֽ��������⡣����������μ���������˹̹����W�о�����Ӌ���SUNCAT���ĵ����Σ�����չ��ԓ��о�����һ����Marzari������Quantum Espresso�_�l�F��е�һ�T��ԓ�Ŀ�о����әC���\�㣬��2009�ꆢ�ӡ�
�������ϻ���M
�����M����ˣ�ֱ��2011��7�£��m�����˔����fԪ�IJ��ϻ���MӋ����MGI�������ϿƌW�ųɞ�������“�m�ĹنT�˽�Ceder���о��dz����ӣ�”���Ԙ˜��c���g������ȫ���WԺ�IJ��ϿƌW�Һ�MGI�����ؕ�James Warren�f����“�˂��ձ��J�R��Ӌ��Cģ�M�Ѱlչ���ˌ������c����a�����HӰ푵��A�Σ��@�����˷Q����ʢ�r��”
������2011��ԓ���h��Ͷ�Y��250���f��Ԫ������ܛ�����ߡ��ռ��͈�挍���Ę˜ʻ���������Ҫ��W��Ӌ����ϿƌW���ġ�У�H�����Լ����w�����о��������@�Ͷ�Y���ƌW���˶���Ƅ����ã��҂��в���֪��Ceder��ʾ��“�@һ�e��@���H�S����Ҳ���F��һЩƫ���Щ�F��_ʼ�Q�Լ����о����@���ǣ�Ȼ���@Щ�c�о����]��ʲôϵ��”
�������^�����Դ_����һ�c�ǣ�MGIּ�ڎ���Ceder�������о��ߌ��F���ό����ھ��������Ը����2011��ף��ܰmҪ��Ceder��Persson�������IJ��ϻ���MӋ���Ğ����Ӌ�����ŗ���“����M”�˺����Ա����c���ҹ������������꣬�ڶſ˴�W���g�о���ܛ�����A�ϣ�Curtarolo�Ƴ����Լ��Ĕ�����——AFLOWlib��
����2013�꣬�����Z���ݰ���˹�D������W���о��ˆTChris Wolverton�Ƴ����_�����Ӳ��ϔ����죨OQMD)�����f��“�҂����b�˲���Ӌ����AFLOWlib�Ŀ��w˼·�����҂���ܛ���͔������Ԯa���N��”
�����@���������칲��ğo�C���w�Y��������@ȡ�Ľ����f�N������֪���ϔ������@Щ�������ѽ������ڌ���Һ�Փ���г��F�^һ�Σ���������ʹ�������δ�õ������yԇ���������²��ϵ��Ԯa�������c��
��������������IJ�֮ͬ̎�������������ļ��O���ϡ�����Ӌ�����������^�٣��s15000����Ceder��Persson���늳��о��еó���Ӌ��Y����“ֻ�д_����Ӌ��Y���Ĝʴ_�Ժ��о������ԣ��҂��ŕ�������������С�”Persson�f��
���������13�f���җl�Y���������K�_�����ᰢ����˹��W�ļ{��ײ��ϻ���M�����A�y�ó��������Pע��ʯ�ͽ����ЙC��ܣ����w�Y���Ў���Ҏ�����؏�С�ĺ��d����ϣ����Բ������w���ӣ��������������̼��
����AFLOWlib�����Ĕ����죬���г��^һ���f�IJ�ͬ���Ϻ�һ�|���ҵ����܌��ԡ�Curtarolo��ʾ���Ǖr�����Ҳ�����˔����fӛ�ļ��O���ϣ������S���ڬF��������һ�D�۵Ĺ������ʧ�ˡ�“���Ǯ���Lԇȥ�A�y�������ijһ���٣�����ؓ�����ˡ�”
�������磬��������AFLOWlib�Ĕ����о���ʲôһЩ�Ͻ���Ժϳɽ��ٲ�����һ�N������ʽ����o���^�Y���x����ԓ���������늴Ō��ԣ����о��Y���@ʾ�������γɄ��ă���֮�����ڲ��������w�Y���Ĕ������������@Щ���w�Y����“���B”�ںϽ���s�^����“���”��
����Wolverton��QQMD������s40�f������ϣ���������Ȼ�ձ�l�F��һϵ�о��w�Y��Ӌ��ó���Wolverton�ĈFꠎ��x����Ԫ�����ڱ���ÿһ�����֣���“�b�”�@Щ���ϡ�
����QQMD���w�˴������}⁵V——�@�N���w����չʾ������עĿ�����ܣ��糬���Լ�����̫���늳��_�l����ӡ����˼�x��ԓ�Ŀ����_���ԣ��Ñ���������X�����d���������죬�����H�H�ǂ����о��Y����
�������ϔ����춼߀̎�ڽ��O�A�Σ���������ȻҪ���M�����r�g���M����Ļ��������Ӌ�㣻�������J��Ŀǰ��Ӌ���h�������ơ�
�����������еĴ��a�����A�����w�Y���ķ����c���s�o���ܺõ��A�����w�Y��������չ���ߌ�����ܣ���ˣ��������������ư댧�w�ķǽ��١�Marzariָ������ʹ����Ӌ����ϿƌW�lչ��õ��I��——늳ز��ϣ�Ҳ���ڰ����ƽ���`�
����ʧ֮���壬և��ǧ�Curtarolo��ʾ��“���ϣ���Щ�`���Դ����Փ�������҂����h�o���m��������”
���������F꠶��ڸ��M�����ļ��g���{��Ӌ�㷨����ϵ�y���`���ͬ�r�������������F꠵��Ñ��ѽ����Ô����_ʼ�ˌ�����Ӌ���ѽ��_���ˎׂ�����ǰ����ꎘO���ϣ����ܱ������늳��еĬF�����Ҫ�ã�����߀�l�F���܉�����̫���늳ز���ͮa��Ч�ʵĽ��������
����������Щ�r���Զ�������һ�WУ���о��ˆTʹ�� AFLOWlib��Ĕ����A��20�N����˹�Ͻ�һ�N�����ڂ���������X�������Ĵ��F�������ɹ��ϳ������еăɷN�Ͻ𣬲���ʾ���ߵĴ��Ԍ����c�A��ֵ�dz��ӽ���
�����������W�^
�������ϻ���M�W�ѽ������˚W�^���M���������Q����׃�������磬��ʿ������MARVEL��һ��Ӌ����ϿƌW�M��������ɣ�������WԺ���ף���Marzari���I���ߡ�
���������µ�Ӌ��ƽ�_��Marzari��������������ƵĔ����졣����ԓ������z���ɆΌ�ԭ�ӻ���Ә��ɵ�“���S”���ϣ���ʯī���@��ϼȿ������ڼ{����ӣ��ֿ������t�W�b�á�
���������ҵ��õĂ��x���ϣ�Marzari�����^15�f��֪�����M�������^��“Ӌ�Ƥ”��Ӌ���һ����ͨ���w������xһ����Ҫ����������������Щ�r�����쌢�������Marzari�A�y���Ǖr�����\���ѽ����w��1500�N������“���S”�Y�������ں��m�Č�����M�Йz
����Ӌ�㻯�W��Berend Smit��������һ����ɣ�������WԺ���ģ����ھ��a����ǧ������İ�����˹ɽ�}�ϡ�ԓ�����������аl�㷨���A�������fӋ�ļ{���ʯ�ͽ����ЙC��ܡ����⣬߀���������沿�R�e���g���㷨�����ڒ���һ���Ŀנ��ΠȻ������т��x���ϣ����ջ�ʯȼ�Ϲ��S�����ŷŵĶ�����̼��
����Smit�Ĺ���߀��ʾ�˲��ϻ���M��ȱ�c���S���о���ϣ���{��ײ��ϴ�����g��С���������������܇ˮ�䡣Ȼ�����ڒ�������65�fӋ����Ϻ�Smit�F꠰l�F�փ���������Ѵ��ڡ��²��σH�H��Щ�S�M�����������C���O������ԴĿ��——���F���郦����ش��g�M����Ҳ���@�ò��F����
����������������һ�����ˌ�ζ�����ϻ���M�W�ڌ��F�����ij��Zǰ��߀��Ҫ�˷��S�����y�������������y���ǣ�Ӌ��C��ģ߀�o���ҳ�������Ȥ�²��ϵķ��������e�f�|�����}�ˡ�
����“�҂�һֱ������P�������|����Ȥ�O�룬”Ceder�f��“�@Щ�O�룬�Еr����ܾ͌��F�ˡ����Еr�������M����6�����о����҂�Ҳ�]�нz���^�w���҂�������֪�������Ƿ����_������ǿ������ж��١�”
����Ceder��Curtarolo���ڇLԇ���M�C���W���㷨������֪�����^������ȡҎ�t��ָ��������ĺϳɡ�
������һ�������ǣ����ϻ���Mһֱ���ڹ��̎����Q�Ĺ����Բ����У��������΄��аl�]���õĻ��������̫���늳������չ⾀������ԓ���g�����ܺܺõ������о��Y���Բ��ϣ���䓣����w�C�C����������l�әC���@������T�珗�Ժ�Ӳ�ȵęC������ȡ�Q�����a�^�̣����@���������W���a���������ġ�
������ʹ���ڹ����Բ��ϣ��F�е�Ӌ��C���aֻ�m���������ľ��w�Y�������@ֻ�Dz����I���һС���֡�Galli��ʾ��“δ��������Ȥ�IJ��Ͽ��������^����Ą����ԽM�b���ɡ�”�����Ǽ{���w�����Ǯ��|���Ͼ��w�ĽM�b��Ҫ�A���@Щ���ϣ�Galli�a�䵽��“����Ҫ����Ӌ����S�����ԣ�ϵ�y����ڼ��r�����ض��ض���������”�������S�࣬“���nj����\���ڸ�ͨ���о���Ӌ��ɱ����fʮ�ָ߰���”
�������ڶ��ԣ�����и���Ĕ������Q�����Ը��õؙz�Ӌ��Y�����������ơ�Ŀǰ��Ceder���c��ʡ�����ĈF�һ���о�����ܛ����ͨ�^��x���ϿƌW���Փ�ģ��Ԅ��Ԙ˜ʸ�ʽ�ṩ���w�Y�������P��Ϣ��“�҂�Ӌ����δ��ׂ��£����@Щ�����������Ӌ���С�”
�����L�ڶ��ԣ�Ħ�����Ɍ�����һ�����ã��S��Ӌ������������ߣ�һЩĿǰӋ��C�o�����F�ļ��g�ܿ쌢��׃�ÿ��С�
����Marzari��ʾ��“�҂��ѽ��߳�Ӌ����ϿƌW���ֹ��r�������M���ˮa�I���A�Ρ��F�ڣ��҂����Ԅ���ģ�M�b��朣���������Ͷ��ʹ�ã���һ�Nȫ�µķ�ʽ̽�����}��”Ŀǰ�Ј��Ϻ��]��Ӌ���A�����ϡ�Galli�f��“��ʮ����أ��������Ǖr�͕��кܶ��ˡ�”




�����Wע�� ����Դ��XXX�����Ї�늳��ˣ�������Ʒ�����D�d������ý�w���D�dĿ�����ڂ��f������Ϣ�������������Wٝͬ���^�c�͌����挍��ؓ؟��
������Ʒ���ݡ������������}��Ҫͬ���Wϵ�ģ�Ո��һ�܃��M�У��Ա��҂����r̎����
QQ��503204601
�]�䣺cbcu@www.astra-soft.com



-
2020���늳��ИI�о����
2021-05-11 11:24 -
ͻ�l������һ����Iֹͣ���I����ɢ�T����
2021-05-11 10:02 -
4���҇�����늳��b܇��ͬ������134.0%
2021-05-13 08:26 -
��ο���Pack���F䇺���Ԫ����
2021-06-01 09:25 -
�ɳ�������\�՚�늳أ��Mչ�������δ��
2021-05-19 10:59 -
���_�M�h䇘I�ļҵ�
2021-06-03 09:46 -
��늳ػġ����u�����a��늄���܇��܇��Ҫ���������ˣ�
2021-06-01 21:22 -
�P����������x��늳����B�mʽ��ո���ϵ�y���gҎ�����ȃ���ИI�˜ʵĺ���������Ҋ����
2021-05-31 22:53

�rֵ�ɾ��ИIƷ�ƣ����\�����ṩ���������YӍ
��ICP��09081210̖
 ��I��̖
��I��̖ �Ź���̖
�Ź���̖